Robots.txt file एक छोटा सा Text फ़ाइल होता है जो आपके साइट के Root folder में रहता है। यह सर्च इंजन Bots को बताता है कि साइट के किस भाग को Crawl और Index करना है और किस भाग को नहीं।
यदि आप इसे Edit/Customize करते समय थोड़ी सी भी गलती करते है, तो सर्च इंजन Bots आपके साइट को क्रॉल और Index करना बंद कर देंगे और आपकी साइट सर्च रिजल्ट में नजर नहीं आयेगी।
इस आर्टिकल में, मैं आपको बताऊंगा Robots.txt file क्या है और SEO के लिए एक Perfect Robots.txt file कैसे बनाये।
कंटेंट की टॉपिक
Robots.txt वेबसाइट के लिए क्यों आवश्यक हैं
सर्च इंजन Bots जब वेबसाइट और ब्लॉग पर आते हैं, तो वे robots file को फॉलो करते है और कंटेंट को crawl करते हैं। लेकिन आपकी साईट में Robots.txt file नहीं होगी, तो सर्च इंजन Bots आपके वेबसाइट के सभी कंटेंट को index और crawl करना शुरू कर देंगे जिन्हें आप Index करना नहीं चाहते हैं।
सर्च इंजन Bots किसी भी वेबसाइट को इंडेक्स करने से पहले robots file को खोजते हैं। जब उन्हें Robots.txt file द्वारा कोई Instructions नहीं मिलता है, तो ये वेबसाइट के सभी कंटेंट को Index करना शुरू कर देते हैं। और कोई Instructions मिलता है, तो उसका पालन करते हुए वेबसाइट को Index करते हैं।
अतः इन्हीं कारणों से Robots.txt file की आवश्यक पड़ती है। अगर हम इस फाइल के द्वारा सर्च इंजन Bots को Instructions नहीं देते हैं, तो वे हमारी पूरी साईट को तो Index कर लेते हैं। साथ ही कुछ ऐसे भी डेटा को index कर लेते हैं, जिन्हें आप index नहीं करना चाहते थे।
Robots.txt फाइल के फायदे
- सर्च इंजन Bots को बताता है कि साइट के किस भाग को Crawl और Index करना है और किस भाग को नहीं।
- किसी खास फाइल, फोल्डर, इमेज, pdf आदि को सर्च इंजन में Index होने से रोका जा सकता है।
- कभी कभी सर्च इंजन क्रॉलर आपके साईट को भूखें शेर की तरह क्रॉल करते है, जिससे आपकी साईट performance पर असर पड़ता है। लेकिन आप अपने robots file में crawl-delay जोडकर इस प्रॉब्लम से छुटकारा पा सकते है। हालंकि Googlebot इस Command को नहीं मानता है। लेकिन Crawl rate को आप Google Search Console में सेट कर सकते है। यह आपके सर्वर को ओवरलोड होने से बचाता है।
- किसी भी वेबसाइट के पुरे सेक्शन को Private कर सकते है।
- Internal search results page को SERPs में दिखाने से रोक सकते हैं।
- आप low quality pages को ब्लाक करके अपनी Website SEO में सुधार कर सकते है।
Website में Robots.txt फाइल कहाँ रहता है
यदि आप एक WordPress user है, तो यह आपके साईट के Root folder में रहता है। अगर इस लोकेशन में यह फाइल नहीं मिलती है, तो सर्च इंजन bot आपकी पूरी वेबसाइट को Index करना शुरू कर देते हैं। क्योंकि सर्च इंजन bot Robots.txt फाइल के लिए आपकी पूरी वेबसाइट को सर्च नहीं करते हैं।
यदि आपको पता नहीं है कि आपकी साईट में robots.txt file है या नहीं? तो सर्च इंजन address bar में बस आपको यह type करना है – example.com/robots.txt
आपके सामने एक text पेज open हो जाएगी जैसा कि आप स्क्रीनशॉट में देख सकते है।
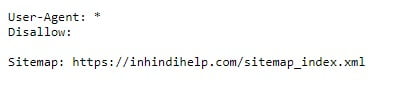
यह InHindiHelp की robots.txt फाइल है। यदि आपको ऐसी कोई txt page नहीं दिखती है, तो आपको अपने साईट के लिए एक robots.txt फाइल बनानी होगी।
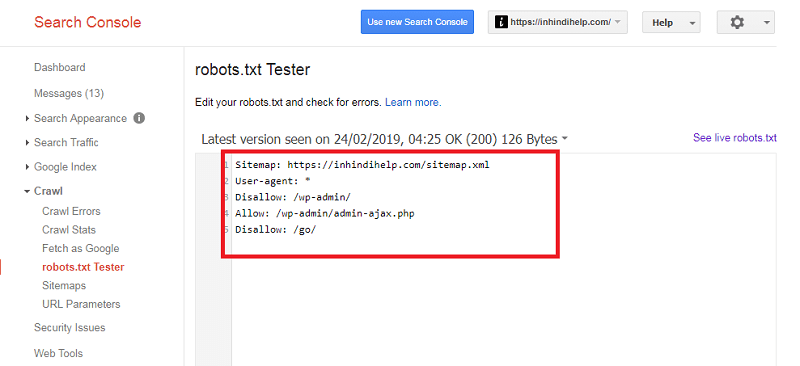
इसके अलावा आप Google Search Console tools में जाकर इसे चेक कर सकते है।
Robots.txt File की Basic Format
Robots.txt फाइल की Basic format बहुत सिंपल है और यह कुछ इस तरह दिखती है,
User-agent: [user-agent name]
Disallow: [URL या पेज जिसे आप क्रॉल नहीं करना चाहते हैं]
इन दो command को एक complete robots.txt फ़ाइल माना जाता है। हालांकि एक robots file में user agents और directives के कई commands हो सकते हैं (disallows, allows, crawl-delays आदि)।
- User-agent: Search Engines Crawlers/Bots होते है। अगर आप सभी सर्च इंजन bots को same instruction देना चाहते हैं, तो User-agent: के बाद * चिन्ह का प्रयोग करें। जैसे – User-agent: *
- Disallow: यह files और directories को index होने से रोकता है।
- Allow: यह सर्च इंजन bots को आपके कंटेंट crawl और index करने की अनुमति प्रदान करता है।
- Crawl-delay: पेज कंटेंट को loading और crawling करने से पहले कितने सेकंड तक bots को इंतजार करना है।
सभी Web Crawlers को वेबसाइट Index करने से रोकना
User-agent: *
Disallow: /
Robots.txt फ़ाइल में इस command का उपयोग करके सभी web crawlers/bots को वेबसाइट crawling करने से रोक सकते है।
सभी कंटेंट को Index करने के लिए सभी Web Crawlers को अनुमति देना
User-agent: *
Disallow:
Robots.txt फ़ाइल में यह command सभी सर्च इंजन बोट्स को आपकी साईट के सभी पेज क्रॉल करने की अनुमति देता है।
एक Specific Folder को Specific Web Crawlers के लिए Block करना
User-agent: Googlebot
Disallow: /example-subfolder/
यह command केवल Google crawler को example-subfolder क्रॉल करने से रोकता है। लेकिन यदि आप सभी Crawlers को Block करना चाहते है, तो आपकी Robots फ़ाइल इस प्रकार होगी।
User-agent: *
Disallow: /example-subfolder/
एक Specific Page (Thank You Page) को Index होने से रोकना
User-agent: *
Disallow: /page URL (Thank You Page)
यह सभी crawlers को आपके पेज URL को क्रॉल करने से से रोकेगा। लेकिन यदि Specific Crawlers को ब्लाक करना चाहते है, तो आप इसे ऐसे लिखें।
User-agent: Bingbot
Disallow: /page URL
यह कमांड केवल Bingbot को आपके पेज URL को क्रॉल करने से से रोकेगा।
Robots.txt File में Sitemap Add करना
Sitemap: https://www.example.com/sitemap.xml
आप अपनी sitemap को robots.txt में कही भी add कर सकते है – सबसे उपर या एकदम नीचे। यहाँ एक गाइड है – Robots.txt फाइल में Sitemap कैसे Add करें और यह क्यूँ जरूरी है?
आप इस आर्टिकल से संबंधित किसी भी प्रकार के प्रश्न या सुझाव के लिए कमेंट कर सकते हैं।अगर यह आर्टिकल आपके लिए मददगार साबित हुई है, तो इसे शेयर करना न भूलें!
इसे भी पढ़ें:
Thanks sir, you provide best information, I waited your next blog.
Very helpful information thanks for sharing.
Bhai maine apne blog me pahle robot.TXT file daali thi lekin ab delete kar di hai to kya koi problem hogi.
Aur jab file thi tab search bar me apne website ke aage robot.TXT file likhkar search karta tha to show karta tha- क्षमा करे यहां कुछ नहीं है
Nice very good knowledge sharing sir very helpful for me
Thank you keep visiting
Thank you Sir.
You provide very valuable information. Its can help every blogger to improve their blog.
Thank you keep visiting
अमन भाई आपका लेख काफ़ी लाभदायक होता है। खास कर नए वेबसाईट डिजाइनर य ब्लोगर के लिए। मैं कह सकता हूँ की आप के पोस्ट से बहुत कुछ आसानी से सीखा जा सकता है। आप को बहुत बहुत शुभ कामना।
Good post